 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Solving Mixed-Hierarchy Games with Quasi-Policy Approximations
Feb 02, 2026Multi-robot coordination often exhibits hierarchical structure, with some robots' decisions depending on the planned behaviors of others. While game theory provides a principled framework for such interactions, existing solvers struggle to handle mixed information structures that combine simultaneous (Nash) and hierarchical (Stackelberg) decision-making. We study N-robot forest-structured mixed-hierarchy games, in which each robot acts as a Stackelberg leader over its subtree while robots in different branches interact via Nash equilibria. We derive the Karush-Kuhn-Tucker (KKT) first-order optimality conditions for this class of games and show that they involve increasingly high-order derivatives of robots' best-response policies as the hierarchy depth grows, rendering a direct solution intractable. To overcome this challenge, we introduce a quasi-policy approximation that removes higher-order policy derivatives and develop an inexact Newton method for efficiently solving the resulting approximated KKT systems. We prove local exponential convergence of the proposed algorithm for games with non-quadratic objectives and nonlinear constraints. The approach is implemented in a highly optimized Julia library (MixedHierarchyGames.jl) and evaluated in simulated experiments, demonstrating real-time convergence for complex mixed-hierarchy information structures.
Generalized Information Gathering Under Dynamics Uncertainty
Jan 29, 2026An agent operating in an unknown dynamical system must learn its dynamics from observations. Active information gathering accelerates this learning, but existing methods derive bespoke costs for specific modeling choices: dynamics models, belief update procedures, observation models, and planners. We present a unifying framework that decouples these choices from the information-gathering cost by explicitly exposing the causal dependencies between parameters, beliefs, and controls. Using this framework, we derive a general information-gathering cost based on Massey's directed information that assumes only Markov dynamics with additive noise and is otherwise agnostic to modeling choices. We prove that the mutual information cost used in existing literature is a special case of our cost. Then, we leverage our framework to establish an explicit connection between the mutual information cost and information gain in linearized Bayesian estimation, thereby providing theoretical justification for mutual information-based active learning approaches. Finally, we illustrate the practical utility of our framework through experiments spanning linear, nonlinear, and multi-agent systems.
Training Report of TeleChat3-MoE
Dec 30, 2025TeleChat3-MoE is the latest series of TeleChat large language models, featuring a Mixture-of-Experts (MoE) architecture with parameter counts ranging from 105 billion to over one trillion,trained end-to-end on Ascend NPU cluster. This technical report mainly presents the underlying training infrastructure that enables reliable and efficient scaling to frontier model sizes. We detail systematic methodologies for operator-level and end-to-end numerical accuracy verification, ensuring consistency across hardware platforms and distributed parallelism strategies. Furthermore, we introduce a suite of performance optimizations, including interleaved pipeline scheduling, attention-aware data scheduling for long-sequence training,hierarchical and overlapped communication for expert parallelism, and DVM-based operator fusion. A systematic parallelization framework, leveraging analytical estimation and integer linear programming, is also proposed to optimize multi-dimensional parallelism configurations. Additionally, we present methodological approaches to cluster-level optimizations, addressing host- and device-bound bottlenecks during large-scale training tasks. These infrastructure advancements yield significant throughput improvements and near-linear scaling on clusters comprising thousands of devices, providing a robust foundation for large-scale language model development on hardware ecosystems.
Resolving Conflicting Constraints in Multi-Agent Reinforcement Learning with Layered Safety
May 04, 2025



Preventing collisions in multi-robot navigation is crucial for deployment. This requirement hinders the use of learning-based approaches, such as multi-agent reinforcement learning (MARL), on their own due to their lack of safety guarantees. Traditional control methods, such as reachability and control barrier functions, can provide rigorous safety guarantees when interactions are limited only to a small number of robots. However, conflicts between the constraints faced by different agents pose a challenge to safe multi-agent coordination. To overcome this challenge, we propose a method that integrates multiple layers of safety by combining MARL with safety filters. First, MARL is used to learn strategies that minimize multiple agent interactions, where multiple indicates more than two. Particularly, we focus on interactions likely to result in conflicting constraints within the engagement distance. Next, for agents that enter the engagement distance, we prioritize pairs requiring the most urgent corrective actions. Finally, a dedicated safety filter provides tactical corrective actions to resolve these conflicts. Crucially, the design decisions for all layers of this framework are grounded in reachability analysis and a control barrier-value function-based filtering mechanism. We validate our Layered Safe MARL framework in 1) hardware experiments using Crazyflie drones and 2) high-density advanced aerial mobility (AAM) operation scenarios, where agents navigate to designated waypoints while avoiding collisions. The results show that our method significantly reduces conflict while maintaining safety without sacrificing much efficiency (i.e., shorter travel time and distance) compared to baselines that do not incorporate layered safety. The project website is available at \href{https://dinamo-mit.github.io/Layered-Safe-MARL/}{[this https URL]}
Policies with Sparse Inter-Agent Dependencies in Dynamic Games: A Dynamic Programming Approach
Oct 21, 2024



Common feedback strategies in multi-agent dynamic games require all players' state information to compute control strategies. However, in real-world scenarios, sensing and communication limitations between agents make full state feedback expensive or impractical, and such strategies can become fragile when state information from other agents is inaccurate. To this end, we propose a regularized dynamic programming approach for finding sparse feedback policies that selectively depend on the states of a subset of agents in dynamic games. The proposed approach solves convex adaptive group Lasso problems to compute sparse policies approximating Nash equilibrium solutions. We prove the regularized solutions' asymptotic convergence to a neighborhood of Nash equilibrium policies in linear-quadratic (LQ) games. We extend the proposed approach to general non-LQ games via an iterative algorithm. Empirical results in multi-robot interaction scenarios show that the proposed approach effectively computes feedback policies with varying sparsity levels. When agents have noisy observations of other agents' states, simulation results indicate that the proposed regularized policies consistently achieve lower costs than standard Nash equilibrium policies by up to 77% for all interacting agents whose costs are coupled with other agents' states.
Solving Reach-Avoid-Stay Problems Using Deep Deterministic Policy Gradients
Oct 03, 2024Reach-Avoid-Stay (RAS) optimal control enables systems such as robots and air taxis to reach their targets, avoid obstacles, and stay near the target. However, current methods for RAS often struggle with handling complex, dynamic environments and scaling to high-dimensional systems. While reinforcement learning (RL)-based reachability analysis addresses these challenges, it has yet to tackle the RAS problem. In this paper, we propose a two-step deep deterministic policy gradient (DDPG) method to extend RL-based reachability method to solve RAS problems. First, we train a function that characterizes the maximal robust control invariant set within the target set, where the system can safely stay, along with its corresponding policy. Second, we train a function that defines the set of states capable of safely reaching the robust control invariant set, along with its corresponding policy. We prove that this method results in the maximal robust RAS set in the absence of training errors and demonstrate that it enables RAS in complex environments, scales to high-dimensional systems, and achieves higher success rates for the RAS task compared to previous methods, validated through one simulation and two high-dimensional experiments.
Constraint Inference in Control Tasks from Expert Demonstrations via Inverse Optimization
Apr 06, 2023Inferring unknown constraints is a challenging and crucial problem in many robotics applications. When only expert demonstrations are available, it becomes essential to infer the unknown domain constraints to deploy additional agents effectively. In this work, we propose an approach to infer affine constraints in control tasks after observing expert demonstrations. We formulate the constraint inference problem as an inverse optimization problem, and we propose an alternating optimization scheme that infers the unknown constraints by minimizing a KKT residual objective. We demonstrate the effectiveness of our method in a number of simulations, and show that our method can infer less conservative constraints than a recent baseline method while maintaining comparable safety guarantees.
Cost Inference for Feedback Dynamic Games from Noisy Partial State Observations and Incomplete Trajectories
Jan 04, 2023



In multi-agent dynamic games, the Nash equilibrium state trajectory of each agent is determined by its cost function and the information pattern of the game. However, the cost and trajectory of each agent may be unavailable to the other agents. Prior work on using partial observations to infer the costs in dynamic games assumes an open-loop information pattern. In this work, we demonstrate that the feedback Nash equilibrium concept is more expressive and encodes more complex behavior. It is desirable to develop specific tools for inferring players' objectives in feedback games. Therefore, we consider the dynamic game cost inference problem under the feedback information pattern, using only partial state observations and incomplete trajectory data. To this end, we first propose an inverse feedback game loss function, whose minimizer yields a feedback Nash equilibrium state trajectory closest to the observation data. We characterize the landscape and differentiability of the loss function. Given the difficulty of obtaining the exact gradient, our main contribution is an efficient gradient approximator, which enables a novel inverse feedback game solver that minimizes the loss using first-order optimization. In thorough empirical evaluations, we demonstrate that our algorithm converges reliably and has better robustness and generalization performance than the open-loop baseline method when the observation data reflects a group of players acting in a feedback Nash game.
Forget Less, Count Better: A Domain-Incremental Self-Distillation Learning Benchmark for Lifelong Crowd Counting
May 06, 2022
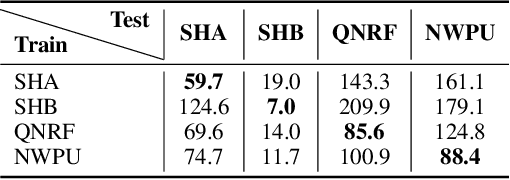
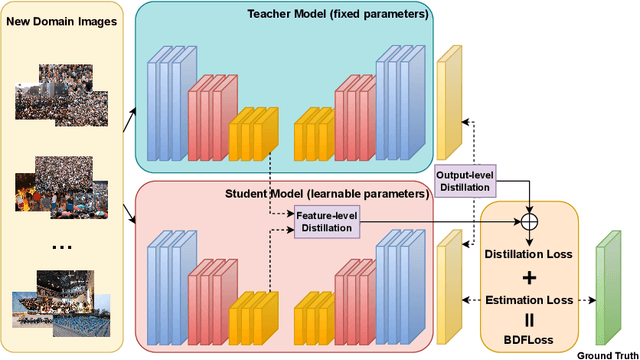
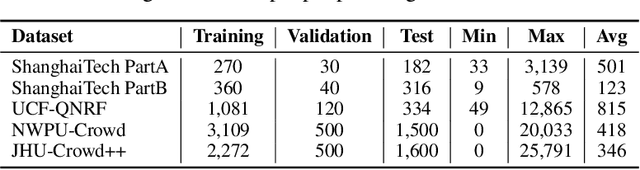
Crowd Counting has important applications in public safety and pandemic control. A robust and practical crowd counting system has to be capable of continuously learning with the new-coming domain data in real-world scenarios instead of fitting one domain only. Off-the-shelf methods have some drawbacks to handle multiple domains. 1) The models will achieve limited performance (even drop dramatically) among old domains after training images from new domains due to the discrepancies of intrinsic data distributions from various domains, which is called catastrophic forgetting. 2) The well-trained model in a specific domain achieves imperfect performance among other unseen domains because of the domain shift. 3) It leads to linearly-increased storage overhead either mixing all the data for training or simply training dozens of separate models for different domains when new ones are available. To overcome these issues, we investigate a new task of crowd counting under the incremental domains training setting, namely, Lifelong Crowd Counting. It aims at alleviating the catastrophic forgetting and improving the generalization ability using a single model updated by the incremental domains. To be more specific, we propose a self-distillation learning framework as a benchmark~(Forget Less, Count Better, FLCB) for lifelong crowd counting, which helps the model sustainably leverage previous meaningful knowledge for better crowd counting to mitigate the forgetting when the new data arrive. Meanwhile, a new quantitative metric, normalized backward transfer~(nBwT), is developed to evaluate the forgetting degree of the model in the lifelong learning process. Extensive experimental results demonstrate the superiority of our proposed benchmark in achieving a low catastrophic forgetting degree and strong generalization ability.
Infinite-Horizon Reach-Avoid Zero-Sum Games via Deep Reinforcement Learning
Mar 18, 2022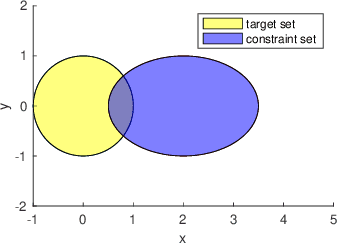
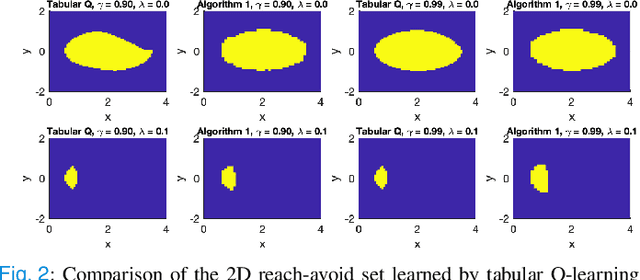
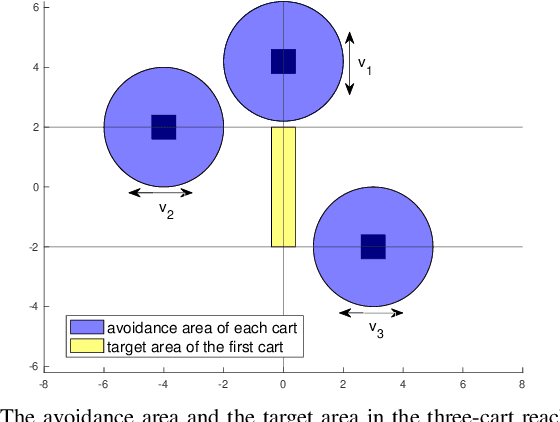
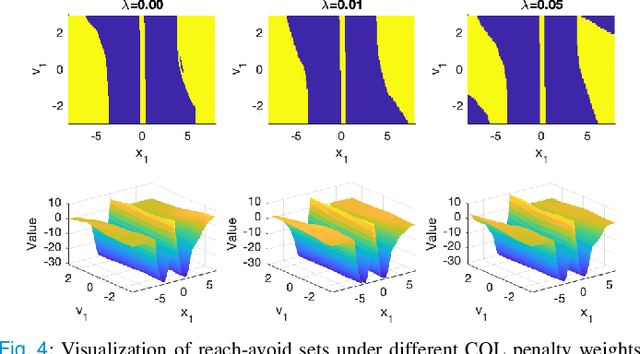
In this paper, we consider the infinite-horizon reach-avoid zero-sum game problem, where the goal is to find a set in the state space, referred to as the reach-avoid set, such that the system starting at a state therein could be controlled to reach a given target set without violating constraints under the worst-case disturbance. We address this problem by designing a new value function with a contracting Bellman backup, where the super-zero level set, i.e., the set of states where the value function is evaluated to be non-negative, recovers the reach-avoid set. Building upon this, we prove that the proposed method can be adapted to compute the viability kernel, or the set of states which could be controlled to satisfy given constraints, and the backward reachable set, or the set of states that could be driven towards a given target set. Finally, we propose to alleviate the curse of dimensionality issue in high-dimensional problems by extending Conservative Q-Learning, a deep reinforcement learning technique, to learn a value function such that the super-zero level set of the learned value function serves as a (conservative) approximation to the reach-avoid set. Our theoretical and empirical results suggest that the proposed method could learn reliably the reach-avoid set and the optimal control policy even with neural network approximation.